多功能streamlit_App
# ✨多功能streamlit_App
深度学习模型部署实现图片检测、视频检测、人脸识别(判断是否是同一个人)、图片分类。
注:人脸识别为自己实现的功能,具体详细的介绍下面已经给出。
demo演示
[video(video-V13rvJQ6-1691047199053)(type-csdn)(url-https://live.csdn.net/v/embed/314987)(image-https://video-community.csdnimg.cn/vod-84deb4/70703b702bc171eebff37035d0b20102/snapshots/3f7b5a63871f461e914a0b5f827b7f58-00005.jpg?auth_key=4843982050-0-0-f5162d684ba0c9f88ee39b03e30de32a)(title-演示demo2)]
安装依赖
pip install -r requirements.txt # 本地安装
运行项目
首先现在人脸识别FaceModel文件夹中进行训练,得到model,然后将Facemodel.py文件中的pkl文件进行替换。然后在终端运行下面的命令。
streamlit run login.py
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-GcD8ZTaY-1691047154847)(./Page_data/users.png)]
根据用户名和密码登录,然后进入主页面。


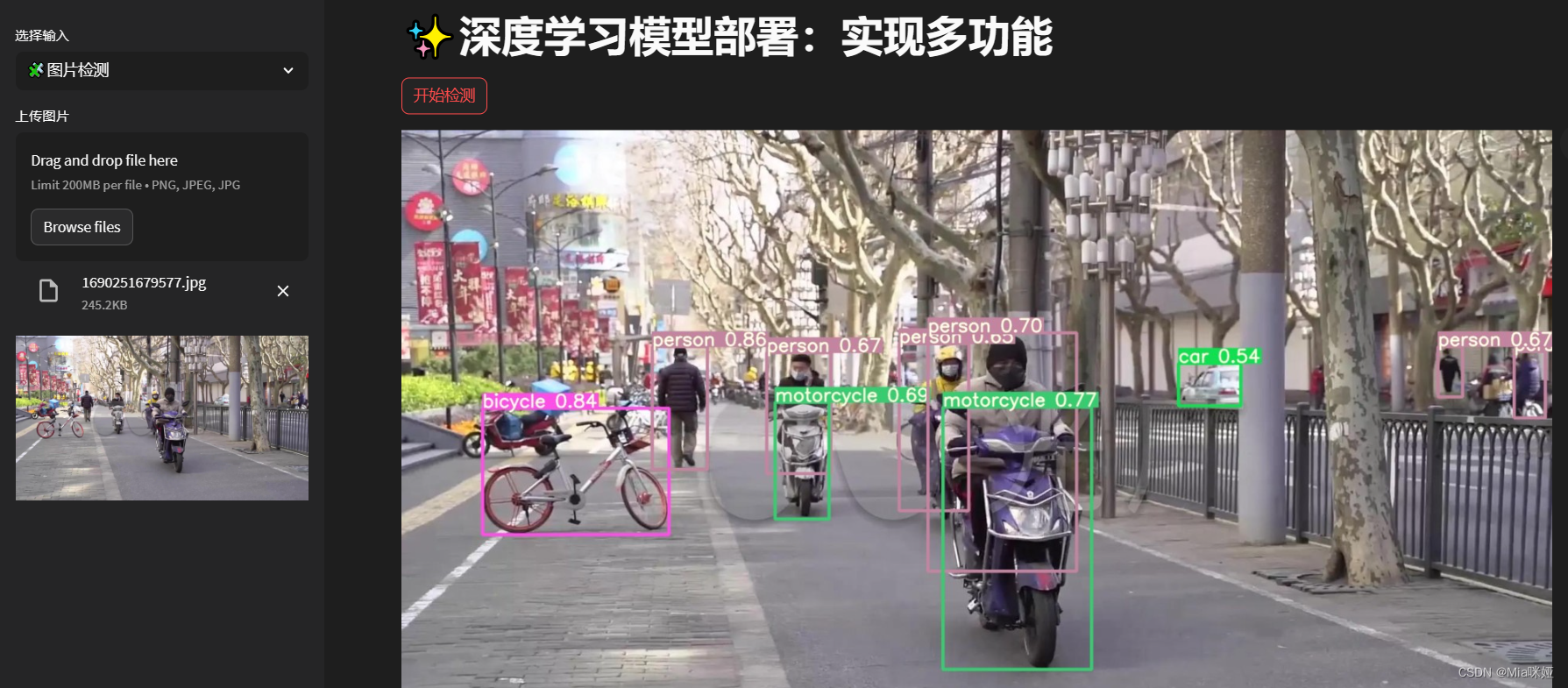
功能介绍
a. 图片检测
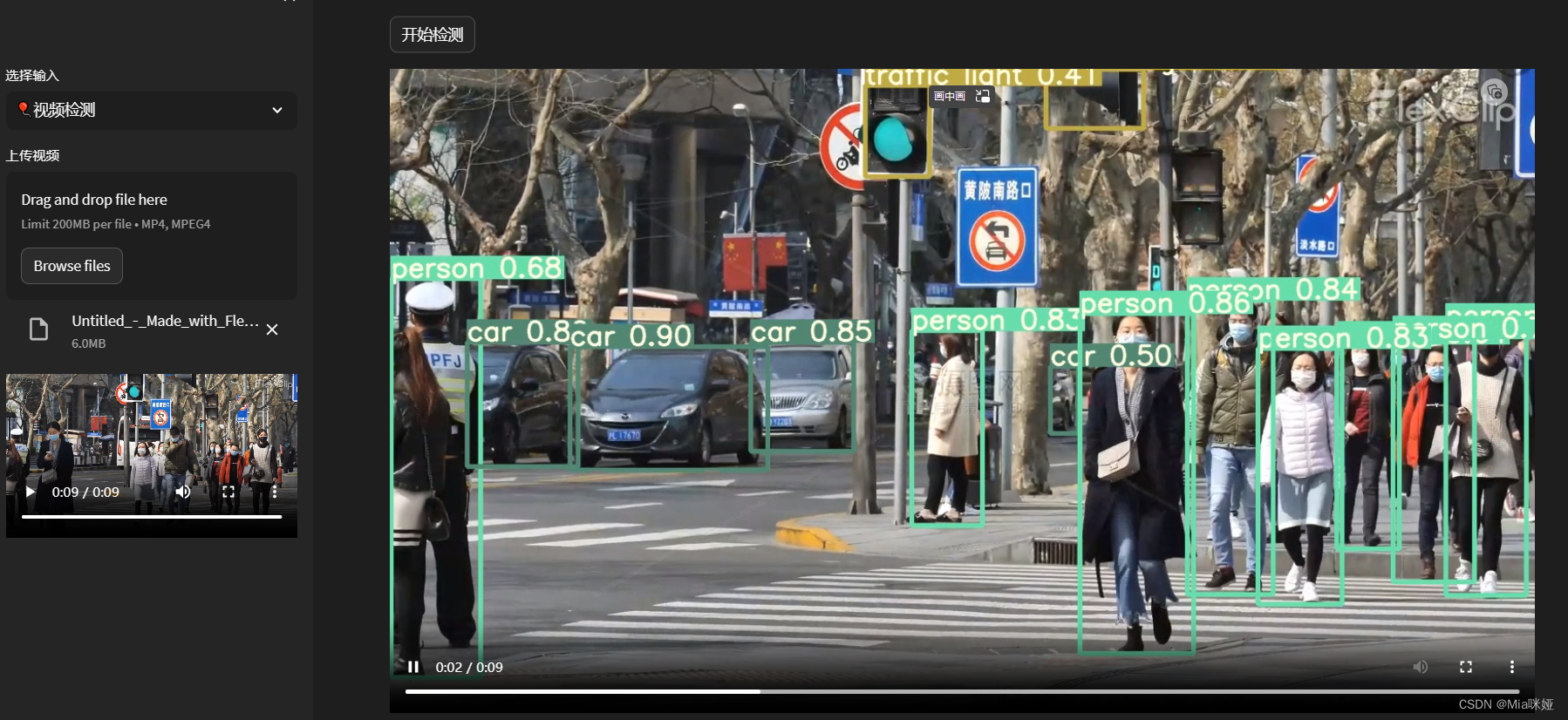
b. 视频检测
c. 人脸识别
由于人脸识别功能是自己写自己训练得到的,所以下面将对代码进行详细介绍。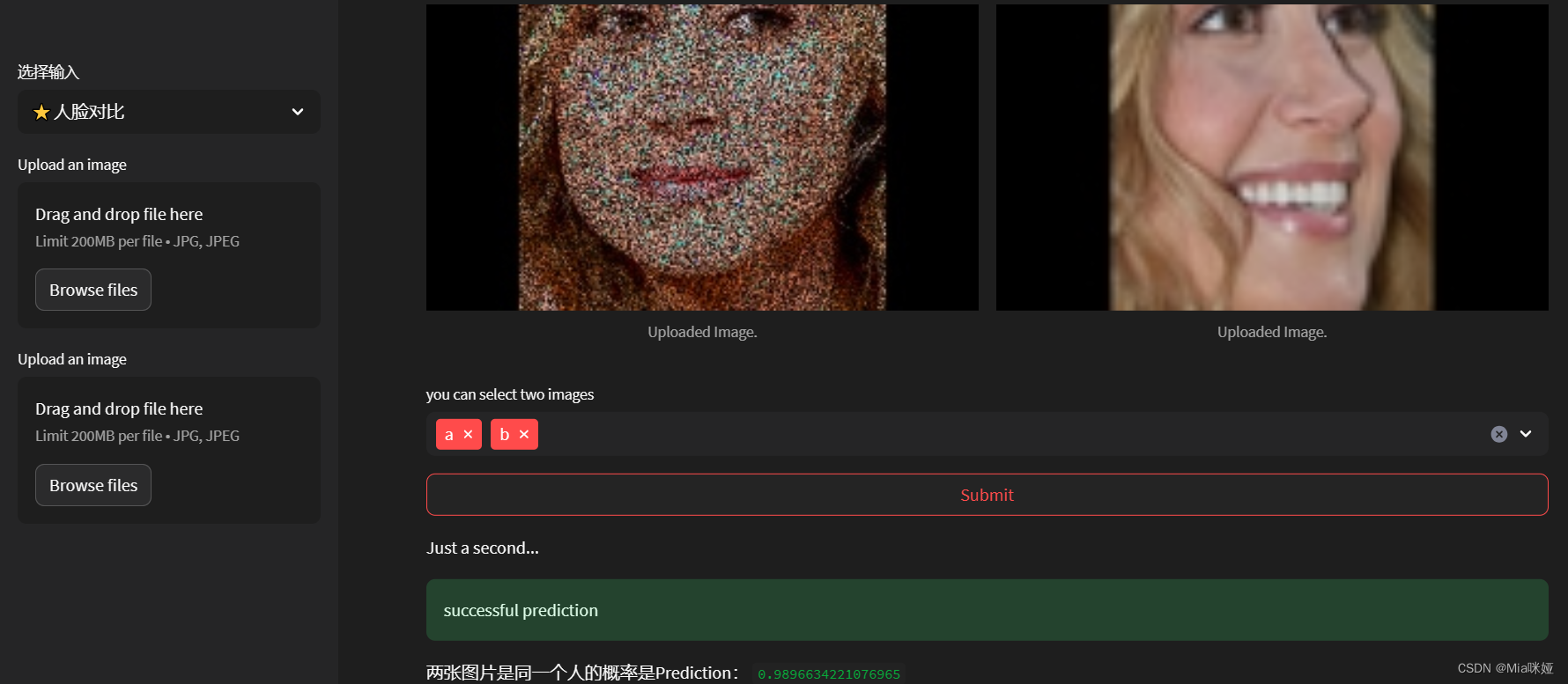
1. 训练模型数据集
1 | CeleA前500个数据集和CASIA数据集 |
2. 数据处理
说明:由于CeleA和CASIA数据集不是单纯的人脸,所以用MTCNN模型提取人脸,然后保存到文件夹中。
2.1 数据预处理
两个数据集包含的总的人脸个数和每个人的人脸个数数量不同,出现了数据不平衡的问题。所以在数据处理阶段我们采用数据融合的方法解决数据不平衡的问题,即将CASIA数据集和CELEA的前500个数据集进行融合。得到是数据存放在中间数据文件夹temp_data中。
CASIA_face_detection.py用于实现CASIA数据集的人脸检测并保存。CASIA数据集中同一个人有5张不同的图片。执行以下命令即可获得预处理后的CASIA数据集。
1 | python CASIA_face_detection.py trainSetCASIA_Dir CASIA_face_train_save_path |
Data_processing_and_detection.py实现CELEA数据集的人脸检测并保存。CELEA数据集同一个人有多张不同的图片(超过5张)。执行以下命令即可获得预处理后的CELEA数据集。
1 | python Data_processing_and_detection.py identify_path img_path save_path CeleA_and_CASIA_save_path |
经过以上两步的处理,我们得到预处理后的CASIA数据集和CELEA数据集。于是将两个数据集合并到同一个文件夹,其中包含1000个人的人脸图像,000-499来源于CASIA数据集,500-1000来源于CeleA数据集。
2.2 MTCNN模型原理
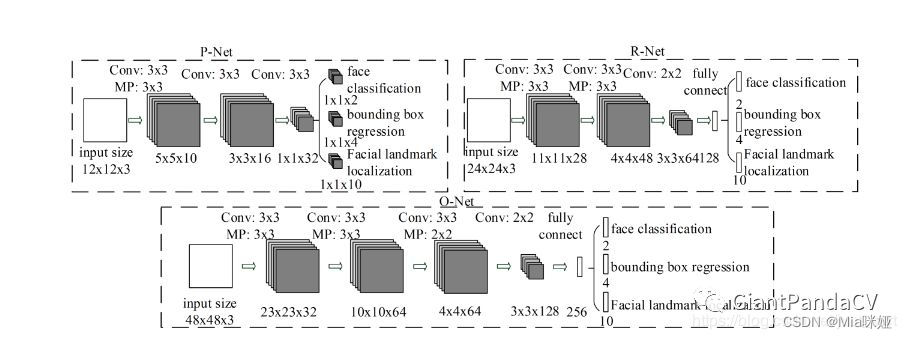
第一阶段是使用一种叫做PNet(Proposal Network)的卷积神经网络,获得候选窗体和边界回归向量。同时,候选窗体根据边界框进行校准。然后利用非极大值抑制去除重叠窗体。第二阶段是使用R-Net(Refine Network)卷积神经网络进行操作,将经过P-Net确定的包含候选窗体的图片在R-Net中训练,最后使用全连接网络进行分类。利用边界框向量微调候选窗体,最后还是利用非极大值抑制算法去除重叠窗体。第三阶段,使用Onet(Output Network)卷积神经网络进行操作,该网络比R-Net多一层卷积层,功能与R-Net类似。网络结构图如下。
3. 模型处理
3.1 模型训练
1 | 执行命令: python train.py trainSetDir modelPath |
数据增强:从数据集随机选择两张图片,对其进行添加椒盐噪声,水平翻转、高斯噪声、平移缩放旋转,其中数据增强是随机的。
1 | transform = transforms.Compose([transforms.Resize((256, 256)), |
训练参数设置
1 | train_epochs = 200 |
3. 2 模型预测
1 | 执行命令: python test.py testSetDir resultPath |
3.3 模型原理
通俗的来说SENet的核心思想在于通过网络根据loss去学习特征权重,使得有效的feature map权重大,无效或效果小的feature map权重小的方式训练模型达到更好的结果。SENet-154的构建是将SE块合并到64×4d ResNeXt-152的修改版本中,该版本采用ResNet-152的块堆叠策略,扩展了原来的ResNeXt-101。SE结构图如下。
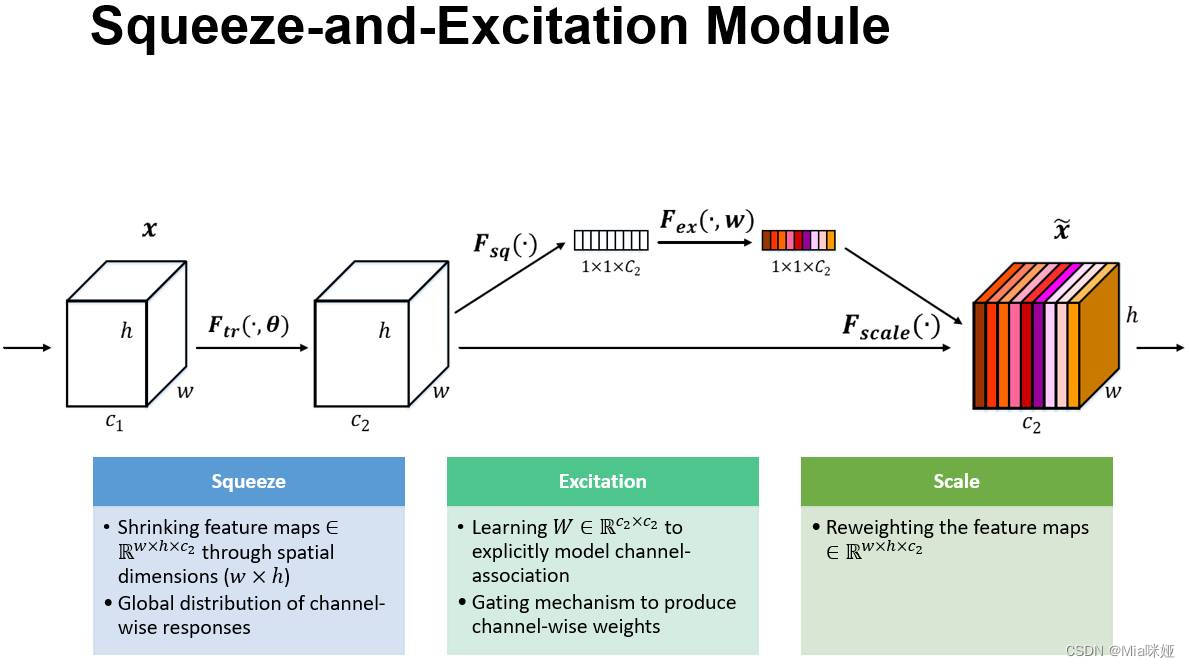
SENET-154与SE存在的其他差异如下:
- 将第一个7×7卷积层替换为3个连续的3 × 3卷积层
每个bottleneck building block的前1 × 1个卷积通道的数量减半,以降低模型的计算成本,同时性能下降最小。- 为了减少过拟合,在分类层之前插入一个
dropout layer (dropout ratio为0.2)。 - 在训练过程中使用了标签平滑正则化。
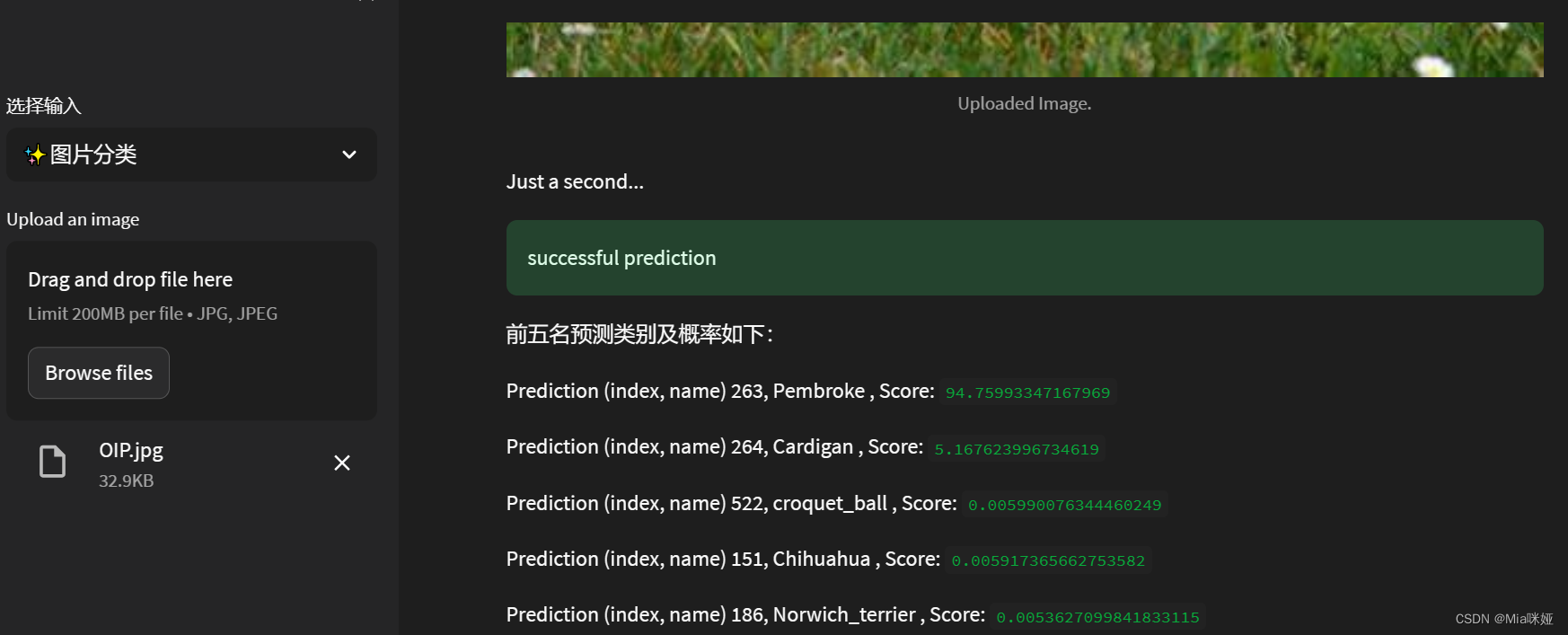
d. 图片分类
参考链接
[1] streamlit
[2] YOLOv5 检测
[3] 图像分类