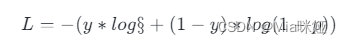# 一、使用预训练的BERT模型解决文本二分类问题
深度学习模型训练的一般步骤:
导入前置依赖
设置全局配置
进行数据读取与数据预处理
构建训练所需的dataloader与dataset
定义预测模型
定义出损失函数和优化器
定义一个验证方法,获取到验证集的精准率和loss。
模型训练,保存最好的模型
加载最好的模型,然后进行测试集的预测
将测试数据送入模型,得到结果
1. 导入前置依赖 1 2 3 4 5 6 7 8 9 10 import osimport pandas as pdimport torchfrom torch import nnfrom torch.utils.data import Dataset, DataLoaderfrom transformers import AutoTokenizerfrom transformers import BertModelfrom pathlib import Path
当我们需要导入项目中的摸个函数时,应该这样操作:
from 文件夹名.某个py文件 import 某个函数
例如在当前目录下有一个FaceModel文件夹,文件夹下有一个faceModel.py, py文件下有一个predict函数,那应该如何操作呢?
1 from FaceModel.faceModel import predict
2.设置全局配置 主要设置一些超参数。超参数是在开 始学习过程之前设置值的参数,而不是通过训练得到的参数数据。通常情况下,需要对超参数进行优化,给学习机选择一组最优超参数,以提高学习的性能和效果。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 batch_size = 16 text_max_length = 128 epochs = 100 lr = 3e-5 validation_ratio = 0.1 device = torch.device('cuda' if torch.cuda.is_available() else 'cpu' ) log_per_step = 50 dataset_dir = Path("./data" ) os.makedirs(dataset_dir) if not os.path.exists(dataset_dir) else '' model_dir = Path("./model/bert_checkpoints" ) os.makedirs(model_dir) if not os.path.exists(model_dir) else '' print("Device:" , device)
3. 进行数据读取与数据预处理 数据预处理的常见步骤:
数据清洗 :检查数据中的缺失值、异常值、重复值等情况,并进行相应处理。可以使用插补方法填充缺失值,剔除异常值或者利用统计方法进行处理。特征选择 :根据实际问题和领域知识,选择最相关和有用的特征。可以使用相关性分析、特征重要性评估等方法进行特征选择。特征缩放 :将不同尺度或数量级的特征进行缩放,以保证模型的准确性和稳定性。常见的特征缩放方法包括标准化和归一化。特征编码 :将非数值型的特征转换为数值型,以便模型可以进行处理。可以使用独热编码、标签编码等方法进行特征编码。数据集划分 :将数据集划分为训练集、验证集和测试集。训练集用于模型训练,验证集用于模型调优和选择,测试集用于评估模型性能。处理类别不平衡 :如果数据集中存在类别不平衡问题,可以采取一些方法来处理,例如欠采样、过采样等。
具体的预处理方法和步骤会根据具体的数据和问题而有所不同。在实际应用中,根据具体情况选择适当的数据预处理方法非常重要,以提高模型的性能和准确性。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 pd_train_data = pd.read_csv('./data/train.csv' ) pd_train_data['title' ] = pd_train_data['title' ].fillna('' ) pd_train_data['abstract' ] = pd_train_data['abstract' ].fillna('' ) test_data = pd.read_csv('./data/test.csv' ) test_data['title' ] = test_data['title' ].fillna('' ) test_data['abstract' ] = test_data['abstract' ].fillna('' ) pd_train_data['text' ] = pd_train_data['title' ].fillna('' ) + ' ' + pd_train_data['author' ].fillna('' ) + ' ' + pd_train_data['abstract' ].fillna('' )+ ' ' + pd_train_data['Keywords' ].fillna('' ) test_data['text' ] = test_data['title' ].fillna('' ) + ' ' + test_data['author' ].fillna('' ) + ' ' + test_data['abstract' ].fillna('' )+ ' ' + pd_train_data['Keywords' ].fillna('' ) validation_data = pd_train_data.sample(frac=validation_ratio) train_data = pd_train_data[~pd_train_data.index.isin(validation_data.index)]
构建数据集,将数据集划分为训练集、验证集和测试集
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 class MyDataset (Dataset) : def __init__ (self, mode='train' ) : super(MyDataset, self).__init__() self.mode = mode if mode == 'train' : self.dataset = train_data elif mode == 'validation' : self.dataset = validation_data elif mode == 'test' : self.dataset = test_data else : raise Exception("Unknown mode {}" .format(mode)) def __getitem__ (self, index) : data = self.dataset.iloc[index] text = data['text' ] if self.mode == 'test' : label = data['uuid' ] else : label = data['label' ] return text, label def __len__ (self) : return len(self.dataset) train_dataset = MyDataset('train' ) validation_dataset = MyDataset('validation' ) tokenizer = AutoTokenizer.from_pretrained("bert-base-uncased" )
4. 构建训练所需的dataloader与dataset 接构造Dataloader,需要定义一下collate_fn,在其中完成对句子进行编码、填充、组装batch等动作:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 def collate_fn (batch) : """ 将一个batch的文本句子转成tensor,并组成batch。 :param batch: 一个batch的句子,例如: [('推文', target), ('推文', target), ...] :return: 处理后的结果,例如: src: {'input_ids': tensor([[ 101, ..., 102, 0, 0, ...], ...]), 'attention_mask': tensor([[1, ..., 1, 0, ...], ...])} target:[1, 1, 0, ...] """ text, label = zip(*batch) print('text:' ,text, 'label:' ,label) text, label = list(text), list(label) src = tokenizer(text, padding='max_length' , max_length=text_max_length, return_tensors='pt' , truncation=True ) print('src:' ,src) return src, torch.LongTensor(label) train_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True , collate_fn=collate_fn) validation_loader = DataLoader(validation_dataset, batch_size=batch_size, shuffle=False , collate_fn=collate_fn)
下面是对BERT模型的详细介绍:
架构 :BERT模型的核心是Transformer架构,它由多个编码器层组成。每个编码器层都由多头自注意力机制(Multi-Head Self-Attention)和前馈神经网络(Feed-Forward Neural Network)组成。预训练阶段 :BERT在预训练阶段通过两个自监督任务来学习文本表示:Masked Language Model(MLM)和Next Sentence Prediction(NSP)。MLM :模型随机地遮盖输入文本的一部分单词,并训练来预测这些被遮盖的单词。这样可以使模型学会理解上下文和句子中的关系以及词汇的表征。NSP :模型输入两个句子,并判断这两个句子是否相邻。这个任务可以使模型学会理解句子级别的关系和上下文之间的相关性。微调阶段 :在预训练阶段得到的BERT模型可以在特定的下游任务上进行微调。这些下游任务可能包括文本分类、命名实体识别、问答等。在微调阶段,BERT模型通过在下游任务上进行有监督学习来进一步优化和适应。输入表示 :BERT模型的输入通常是经过分词(tokenization)后的文本。BERT使用WordPiece分词技术将输入序列拆分为多个子词(subword)。每个子词都有一个唯一的标记,并且可以通过词嵌入得到对应的向量表示。输出表示 :BERT模型在每一层的输出都包含了每个输入的表示。通常情况下,我们只使用最后一层的输出作为输入文本的表示,也可以使用多层的输出进行组合。上下文无关性和上下文敏感性 :BERT模型通过上下文无关的方式进行预训练。这意味着模型可以独立地对每个输入进行编码,而不考虑其上下文信息。在微调和应用阶段,BERT模型可以根据需要进行上下文敏感性编码。
BERT模型的优点 是能够学习到更好的语言表示,能够根据上下文理解词汇的含义和句子的关系,并在各种下游任务上取得了良好的性能。但它也有一些限制,例如计算资源要求较高,模型较大,需要较长的训练时间。
5. 定义预测模型 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 class MyModel (nn.Module) : def __init__ (self) : super(MyModel, self).__init__() self.bert = BertModel.from_pretrained('bert-base-uncased' , mirror='tuna' ) self.predictor = nn.Sequential( nn.Linear(768 , 256 ), nn.ReLU(), nn.Linear(256 , 1 ), nn.Sigmoid() ) def forward (self, src) : """ :param src: 分词后的推文数据 """ outputs = self.bert(**src).last_hidden_state[:, 0 , :] return self.predictor(outputs) model = MyModel() model = model.to(device)
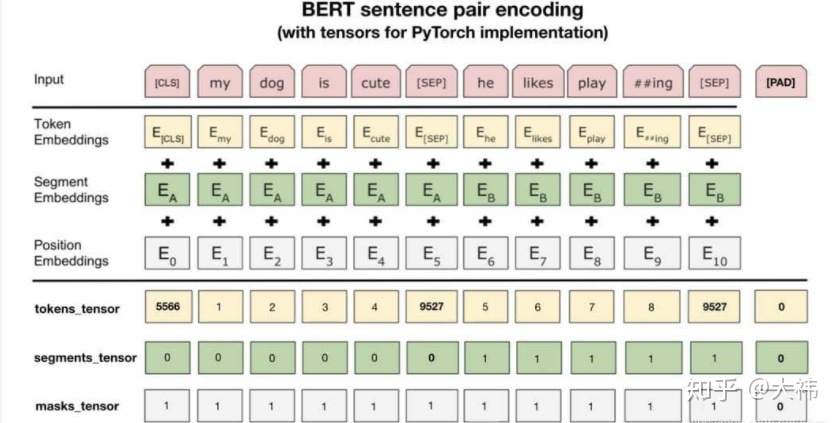
BERT模型在文本前插入一个[CLS]符号,并将该符号对应的输出向量作为整篇文本的语义表示,用于文本分类,如下图所示。可以理解为:与文本中已有的其它字/词相比,这个无明显语义信息的符号会更“公平”地融合文本中各个字/词的语义信息。
6. 定义出损失函数和优化器 二元交叉熵(Binary Cross Entropy) 是一种用于衡量两个概率分布之间差异的损失函数,通常用于二分类问题。
1 2 3 4 5 6 7 8 9 criteria = nn.BCELoss() optimizer = torch.optim.Adam(model.parameters(), lr=lr) def to_device (dict_tensors) : result_tensors = {} for key, value in dict_tensors.items(): result_tensors[key] = value.to(device) return result_tensors
7. 定义一个验证方法,获取到验证集的精准率和loss 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 def validate () : model.eval() total_loss = 0. total_correct = 0 for inputs, targets in validation_loader: inputs, targets = to_device(inputs), targets.to(device) outputs = model(inputs) loss = criteria(outputs.view(-1 ), targets.float()) total_loss += float(loss) correct_num = (((outputs >= 0.5 ).float() * 1 ).flatten() == targets).sum() total_correct += correct_num return total_correct / len(validation_dataset), total_loss / len(validation_dataset)
8. 模型训练,保存最好的模型 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 model.train() if torch.cuda.is_available(): torch.cuda.empty_cache() total_loss = 0. step = 0 best_accuracy = 0 for epoch in range(epochs): model.train() for i, (inputs, targets) in enumerate(train_loader): inputs, targets = to_device(inputs), targets.to(device) outputs = model(inputs) loss = criteria(outputs.view(-1 ), targets.float()) loss.backward() optimizer.step() optimizer.zero_grad() total_loss += float(loss) step += 1 if step % log_per_step == 0 : print("Epoch {}/{}, Step: {}/{}, total loss:{:.4f}" .format(epoch+1 , epochs, i, len(train_loader), total_loss)) total_loss = 0 del inputs, targets accuracy, validation_loss = validate() print("Epoch {}, accuracy: {:.4f}, validation loss: {:.4f}" .format(epoch+1 , accuracy, validation_loss)) torch.save(model, model_dir / f"model_{epoch} .pt" ) if accuracy > best_accuracy: torch.save(model, model_dir / f"model_best.pt" ) best_accuracy = accuracy
9. 加载最好的模型,然后进行测试集的预测 1 2 3 4 5 model = torch.load(model_dir / f"model_best.pt" ) model = model.eval() test_dataset = MyDataset('test' ) test_loader = DataLoader(test_dataset, batch_size=batch_size, shuffle=False , collate_fn=collate_fn)
10. 将测试数据送入模型,得到结果 1 2 3 4 5 6 7 8 9 10 11 results = [] for inputs, ids in test_loader: outputs = model(inputs.to(device)) outputs = (outputs >= 0.5 ).int().flatten().tolist() ids = ids.tolist() results = results + [(id, result) for result, id in zip(outputs, ids)] test_label = [pair[1 ] for pair in results] test_data['label' ] = test_label test_data[['uuid' , 'label' ]].to_csv('submit_task1_test.csv' , index=None )
二、Bert_for_关键词提取 1. 导入前置依赖 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 import pandas as pdfrom sklearn.feature_extraction.text import TfidfVectorizerfrom sentence_transformers import SentenceTransformerfrom sklearn.metrics.pairwise import cosine_similarityfrom warnings import simplefilterfrom sklearn.exceptions import ConvergenceWarningsimplefilter("ignore" , category=ConvergenceWarning) from sklearn.feature_extraction.text import TfidfVectorizertexts=["dog cat fish" ,"dog cat cat" ,"fish bird" , 'bird' ] cv = TfidfVectorizer() cv_fit=cv.fit_transform(texts) print(cv.get_feature_names()) print(cv.vocabulary_ ) print(cv_fit)
2. 读取数据集并处理 1 2 3 4 5 6 7 8 9 10 test = pd.read_csv('./data/testB.csv' ) test['title' ] = test['title' ].fillna('' ) test['abstract' ] = test['abstract' ].fillna('' ) test['text' ] = test['title' ].fillna('' ) + ' ' +test['abstract' ].fillna('' ) stops =[i.strip() for i in open(r'stop.txt' ,encoding='utf-8' ).readlines()]
使用n_gram_range来改变结果候选词的词长大小。例如,如果我们将它设置为(3,3),那么产生的候选词将是包含3个关键词的短语。然后,变量candidates就是一个简单的字符串列表,其中包含了我们的候选关键词或者关键短语。
3. Embeddings 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 model = SentenceTransformer(r'xlm-r-distilroberta-base-paraphrase-v1' ) test_words = [] for row in test.iterrows(): n_gram_range = (2 ,2 ) count = TfidfVectorizer(ngram_range=n_gram_range, stop_words=stops).fit([row[1 ].text]) candidates = count.get_feature_names() print(candidates) title_embedding = model.encode([row[1 ].title]) candidate_embeddings = model.encode(candidates)
4. Cosine Similarity 要找到与文档最相似的候选词汇或者短语。假设与文档最相似的候选词汇/短语,是能较好的表示文档的关键词/关键短语。为了计算候选者和文档之间的相似度,将使用向量之间的余弦相似度,因为它在高维度下表现得相当好。
1 2 3 4 5 6 7 8 9 top_n = 35 distances = cosine_similarity(title_embedding, candidate_embeddings) keywords = [candidates[index] for index in distances.argsort()[0 ][-top_n:]] if len( keywords) == 0 : keywords = ['A' , 'B' ] test_words.append('; ' .join( keywords))
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 print(keywords) ''' 输出结果: ['monomers roasting', 'ara monomers', 'enzyme linked', 'degranulation basophils', 'matrix amount', 'total proteins', 'stimulate degranulation', 'roasting ara', 'allergenicity increase', 'structure ara', 'allergenicity cross', 'allergenicity change', 'proteins iac', 'addition methylation', 'processing roasting', 'food allergy', 'derivatives roasting', 'ara roasted', 'ara matrix', 'processing structure', 'reflect allergenicity', 'oxidation modification', 'allergenicity ara', 'blotting enzyme', 'reduce allergenicity', 'potential allergenicity', 'terms allergenicity', 'roasted matrix', 'peanut allergy', 'matrix peanut', 'methylation oxidation', 'structure allergenicity', 'allergenicity processing', 'allergenicity peanut', 'peanut allergen'] '''
所有的关键词/短语都是如此的相似,所以可以考虑结果的多样化策略。
5. Diversification 结果的多样化需要在关键词/关键短语的准确性(accuracy)和它们之间的多样性(diversity)之间取得一个微妙的平衡(a delicate balance)。使用两种算法来实现结果的多样化。可参考: 基于上下文语境的文档关键词提取
Max Sum Similarity(最大相似度)
Maximal Marginal Relevance(最大边际相关性)
5.1 Max Sum Similarity(最大相似度) 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 import numpy as npimport itertoolsdef max_sum_sim (doc_embedding, word_embeddings, words, top_n, nr_candidates) : ''' 使用余弦相似度计算文档嵌入向量和候选词嵌入向量之间的相似度。 根据余弦相似度的值,选择具有最高相似度的候选词作为候选集合。 构建候选词之间相似度的矩阵。 使用贪心算法,选择使得相似度之和最大化的词组合作为最终的多样化结果。 ''' distances = cosine_similarity(doc_embedding, candidate_embeddings) distances_candidates = cosine_similarity(candidate_embeddings, candidate_embeddings) words_idx = list(distances.argsort()[0 ][-nr_candidates:]) words_vals = [candidates[index] for index in words_idx] distances_candidates = distances_candidates[np.ix_(words_idx, words_idx)] min_sim = np.inf candidate = None for combination in itertools.combinations(range(len(words_idx)), top_n): sim = sum([distances_candidates[i][j] for i in combination for j in combination if i != j]) if sim < min_sim: candidate = combination min_sim = sim return [words_vals[idx] for idx in candidate]
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 max_sum_sim(doc_embedding=title_embedding, word_embeddings=candidate_embeddings, words=candidates, top_n=10 , nr_candidates=10 ) ''' 输出结果: ['potential allergenicity', 'terms allergenicity', 'roasted matrix', 'peanut allergy', 'matrix peanut', 'methylation oxidation', 'structure allergenicity', 'allergenicity processing', 'allergenicity peanut', 'peanut allergen'] ''' max_sum_sim(doc_embedding=title_embedding, word_embeddings=candidate_embeddings, words=candidates, top_n=10 , nr_candidates=20 ) ''' 输出结果: ['derivatives roasting', 'ara roasted', 'ara matrix', 'processing structure', 'oxidation modification', 'reduce allergenicity', 'potential allergenicity', 'peanut allergy', 'matrix peanut', 'allergenicity processing'] '''
较高的nr_candidates值会创造出更多样化的关键词/关键短语,但这并不能很好地代表文档。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 test_words = [] for row in test.iterrows(): n_gram_range = (2 ,2 ) count = TfidfVectorizer(ngram_range=n_gram_range, stop_words=stops).fit([row[1 ].text]) candidates = count.get_feature_names() print(candidates) title_embedding = model.encode([row[1 ].title]) candidate_embeddings = model.encode(candidates) top_n = 35 keywords = max_sum_sim(doc_embedding=title_embedding, word_embeddings=candidate_embeddings, words=candidates, top_n=10 , nr_candidates=10 ) if len( keywords) == 0 : keywords = ['A' , 'B' ] test_words.append('; ' .join( keywords))
5.2 Maximal Marginal Relevance(最大边际相关性) 最大边际相关性试图在文本摘要任务中最小化冗余(minimize redundancy)和最大化结果的多样性。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 import numpy as npdef mmr (doc_embedding, word_embeddings, words, top_n, diversity) : ''' 使用余弦相似度计算每个候选词与文档嵌入向量的相似度以及候选词之间的相似度。 初始化已选择的关键词列表,首先选择与文档嵌入向量相似度最高的候选词作为第一个关键词。 根据要选择的关键词数量 top_n 进行循环迭代,每次选择与已选择关键词之间边际相关性最大的候选词作为下一个关键词。 更新已选择的关键词列表和候选词列表。 ''' word_doc_similarity = cosine_similarity(word_embeddings, doc_embedding) word_similarity = cosine_similarity(word_embeddings) keywords_idx = [np.argmax(word_doc_similarity)] candidates_idx = [i for i in range(len(words)) if i != keywords_idx[0 ]] for _ in range(top_n - 1 ): candidate_similarities = word_doc_similarity[candidates_idx, :] target_similarities = np.max(word_similarity[candidates_idx][:, keywords_idx], axis=1 ) mmr = (1 -diversity) * candidate_similarities - diversity * target_similarities.reshape(-1 , 1 ) mmr_idx = candidates_idx[np.argmax(mmr)] keywords_idx.append(mmr_idx) candidates_idx.remove(mmr_idx) return [words[idx] for idx in keywords_idx]
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 mmr(doc_embedding=title_embedding, word_embeddings=candidate_embeddings, words=candidates, top_n=20 , diversity=0.2 ) mmr(doc_embedding=title_embedding, word_embeddings=candidate_embeddings, words=candidates, top_n=20 , diversity=0.8 ) '''' 同样的,较高的多样性数值会生成非常多样化的关键词/关键短语 '''
参考 [1] AI夏令营 - NLP实践教程 基于上下文语境的文档关键词提取